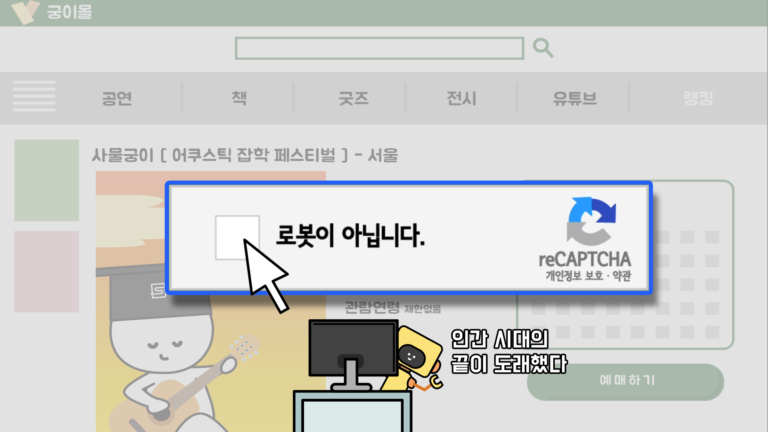
인터넷을 이용하다보면 ‘로봇이 아닙니다.’라는 문구에 체크박스가 함께 뜨는 경우가 있습니다. 이외에도 특정 제시어를 주고 관련 이미지를 선택하라는 경우도 있고, 텍스트 형태로 된 이미지를 보여주면서 보이는 대로 입력하라는 경우도 있습니다.

본 화면으로 넘어가기 위해서는 제시한 임무를 수행해야 하는데, 이러한 절차는 무슨 목적으로 존재하는 걸까요? 진짜 로봇이 컴퓨터를 이용하고 있어서 막기 위함일까요?
이와 같은 기능을 캡차(Chptcha)라고 합니다. 캡차는 컴퓨터(로봇)와 인간을 구별하기 위한 완전 자동화된 공개 튜링테스트(Completely Automated Public Turing test to tell Computers and Humans Apart)의 영어 앞글자를 딴 약자로 여기서 말하는 로봇은 일반적으로 생각하는 기계적인 로봇 장치와는 다릅니다.
인터넷에서의 로봇(이하 ‘봇’)은 여러 웹사이트를 돌아다니면서 데이터를 수집하는 프로그램을 의미하고, 크롤러(crawler)라고도 합니다.
인터넷 공간에는 수많은 봇이 존재하는데, 대표적으로 구글봇이 있습니다. 구글봇은 검색을 더 정확하고 빠르게 하는 목적을 달성하기 위해 여러 웹사이트를 돌며 해당 페이지에서 제공하는 robots.txt 파일에 따라 데이터(Search index)를 수집하고 있고, 이를 통해 사용자가 더 빠른 검색을 할 수 있도록 해줍니다.
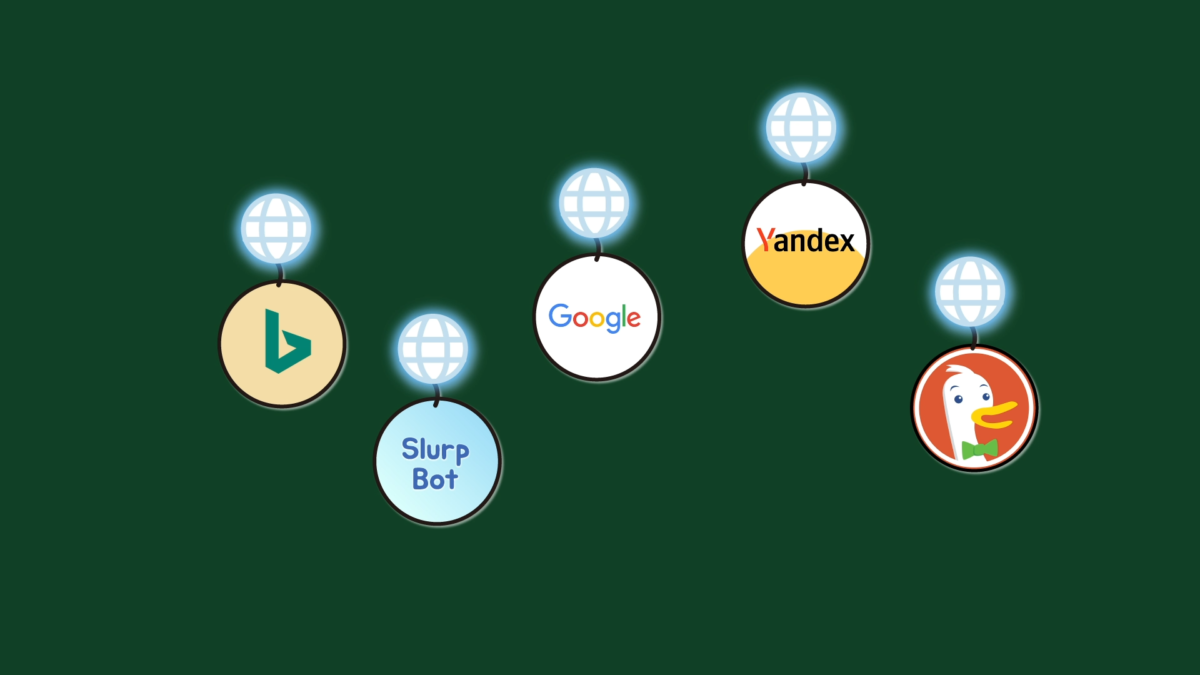
이렇게 인터넷상의 여러 페이지를 돌아다니면서 정보를 수집하는 기술을 크롤링이라고 하는데, 크롤링 기술에 장점만 있는 것은 아닙니다.
봇은 누구나 만들 수 있습니다. 만약 무수한 봇을 생성해서 특정 웹사이트의 데이터를 수집하도록 동작시키면 해당 웹사이트에서 감당할 수 없는 접속 통신량(트래픽)이 발생해 사이트가 마비될 수 있습니다.
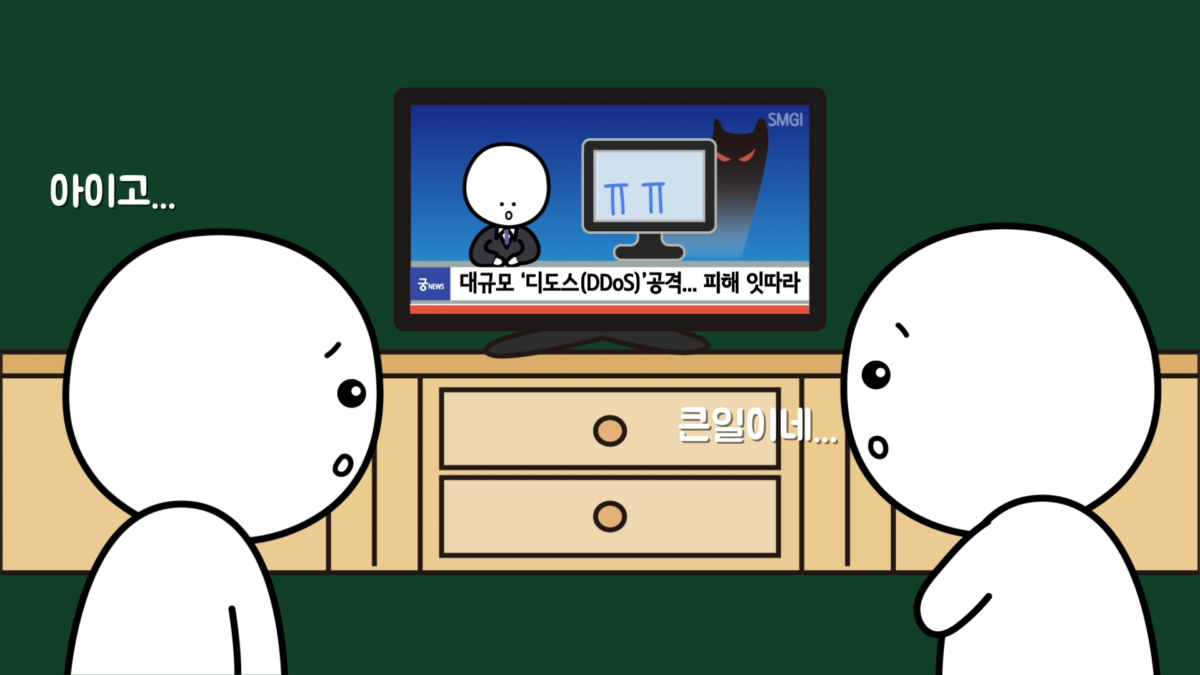
뉴스에서 흔히 보던 DDoS(Denial of Service attack, 분산 서비스 거부 공격) 공격이 이런 형태로 진행되는데, 의도하지 않았다고 하더라도 크롤링 기술의 대표적인 부작용 중 하나입니다.
또한, 크롤링 기술은 웹사이트에서 수집한 데이터를 바탕으로 영리 활동도 할 수 있습니다. 예를 들어서 숙박 중개나 부동산 중개, 채용 중개, 상품 정보 비교 등의 서비스를 제공하는 플랫폼 기업의 경우 그들이 가진 데이터가 매우 중요합니다.
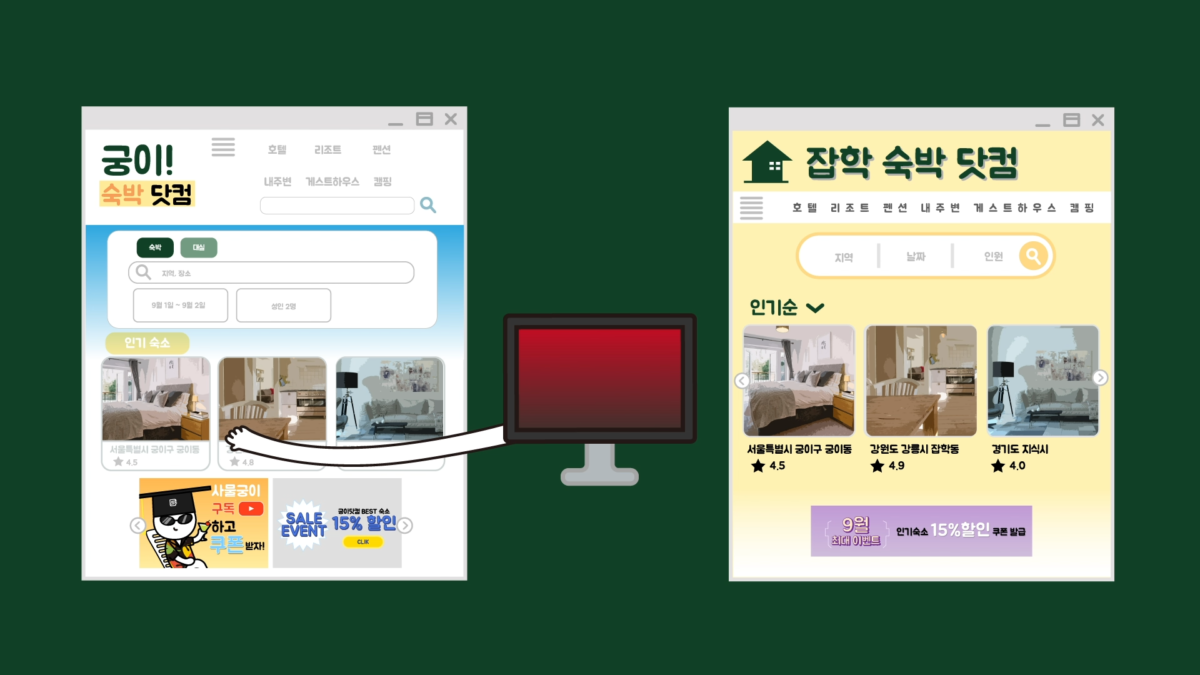
크롤링 기술을 이용해서 해당 데이터들을 수집할 수 있으면 비슷한 플랫폼을 만들 수 있고, 이용자만 모집하면 기존의 플랫폼과 크게 다를 것이 없어집니다. 실제 이와 관련해 플랫폼간 법적 분쟁 사례가 여러 건 있었는데, 법원의 판단이 엇갈리기도 했습니다. 어쨌든 크롤링 기술이 있으면 이런 일도 할 수 있습니다.

이와 같은 무분별한 봇의 사용을 막기 위해 robots.txt라는 파일을 제공하기도 합니다. 이는 봇이 들어가도 되는 도메인과 들어가지 말아야 하는 도메인을 규정짓는 문서로 각 인터넷 서비스 URL 끝에 robots.txt를 붙이면 관련 정보를 볼 수 있습니다. 하지만 이 방식은 그저 권고일 뿐 크롤링 봇에게 강제하지 못합니다,
즉, 강제되는 상황이 아니기에 봇은 어떻게 사용하느냐에 따라 좋을 수도 있고, 나쁠 수도 있습니다. 이런 상황에서 악의적인 동작을 막고, 내 데이터를 지키기 위해 만들어진 것이 캡차 기술입니다.

하지만 이런 캡차 기술을 파훼하는 기술이 계속 진화하고 있습니다. 왜냐하면, 인공지능 기술의 발달로 캡차에서 요구하는 임무를 봇들이 수행하는 경우가 왕왕 있기 때문입니다.
그래서 최근에는 캡차를 풀때 인터넷 트래픽을 분석하거나 마우스의 움직임·이동시간 등을 종합적으로 파악해 사용자에 테스트 요구 없이 자동으로 로봇 여부를 판단하기도 합니다.

그리고 우리가 자주 보는 ‘로봇이 아닙니다.’ 문구에 체크박스가 함께 뜨는 기술은 중간 버전으로 단순히 체크박스에 체크만 하는 것처럼 보여도 체크박스가 뜬 순간부터 마우스와 스크롤이 어떻게 이동하고, 마우스를 클릭한 횟수가 몇 번인지에 따라 판단을 내리는 식입니다. 궁금증이 해결되셨나요?
– 원고 : 익명의 웹개발자
Copyright. 사물궁이 잡학지식. All rights reserved
